AI驅動精準腫瘤學突破:MUSK模型助力醫學研究
在醫學領域,精準診斷和治療決策一直是醫生和患者關注的焦點。然而,面對海量的多模態數據,傳統方法往往力不從心。人工智能(AI)技術的崛起,正為這一難題帶來革命性解決方案。本期文章聚焦于新的研究成果——MUSK模型,通過整合病理圖像和臨床文本數據,不僅實現了跨模態檢索、視覺問答等復雜任務,還在分子標志物預測、癌癥預后和免疫治療反應預測中展現了卓越性能。MUSK的出現,標志著AI在精準腫瘤學領域的應用邁出了關鍵一步。通過本文,您將深入了解AI如何改變醫學的未來,以及它如何為患者帶來更精準、更個性化的治療選擇。
一. 研究背景
臨床決策依賴多模態數據,如臨床記錄和病理特征,但現有方法在整合這些數據方面存在局限。人工智能(AI)在整合多模態數據方面潛力巨大,但高質量標注數據集稀缺,阻礙了模型發展。基礎模型通過大規模預訓練,可在無需額外訓練的情況下應用于多種任務,為醫學AI開辟了新方向。然而,現有視覺-語言基礎模型在病理學領域面臨數據規模不足和任務復雜度有限的挑戰。
為此,本研究提出基于多模態統一掩碼建模變換器(MUSK)的視覺-語言基礎模型。MUSK利用大規模未標注病理圖像和文本數據進行預訓練,并進一步對齊圖像-文本對特征,旨在解決現有模型的局限性。通過廣泛任務評估,MUSK在跨模態檢索、視覺問答、圖像分類、分子標志物預測及臨床結果預測中展現了卓越性能,為精準腫瘤學和多模態AI應用提供了新工具。
二. 文章詳情
文章題目:A vision–language foundation model for precision oncology
中文題目:用于精準腫瘤學的視覺-語言基礎模型
發表時間:2025.02
期刊名稱:Nature
影響因子:50.5
DOI:10.1038/s41586-024-08378-w
三. 研究結果
1. MUSK模型預訓練
本研究開發了基于多模態Transformer架構的視覺-語言基礎模型,作為網絡骨干。模型預訓練分為兩個連續階段。首先,MUSK在5000萬張病理圖像和10億個病理相關文本標記上進行預訓練。這些圖像來源于11,577名患者的約33,000張全切片組織病理學掃描結果,涵蓋了33種腫瘤類型。借鑒BEiT3架構,MUSK模型由共享的自注意力模塊以及針對視覺和語言輸入的獨立專家模塊組成;預訓練通過掩碼建模實現。其次,MUSK在來自QUILT-1M模型的一百萬張圖像-文本對上進行了預訓練,采用對比學習方法以實現多模態對齊。
 Fig1. 數據策劃,模型開發和評估
Fig1. 數據策劃,模型開發和評估2. MUSK在跨模態任務中的卓越表現
MUSK在跨模態檢索和視覺問答(VQA)任務中展現了強大的能力。通過統一掩碼建模技術,MUSK在無需額外訓練的情況下實現了零樣本跨模態檢索,在BookSet和PathMMU數據集上顯著優于其他基礎模型,例如在PathMMU數據集上比第二好的模型(CONCH)高出7.1%。同時,MUSK在視覺問答任務中也表現出色,在PathVQA數據集上的準確率達到73.2%,超越了專門為VQA設計的K-Path VQA模型(準確率:68.9%)。這些結果表明,MUSK能夠有效對齊視覺和語言特征,為跨模態任務提供了高效且通用的解決方案。
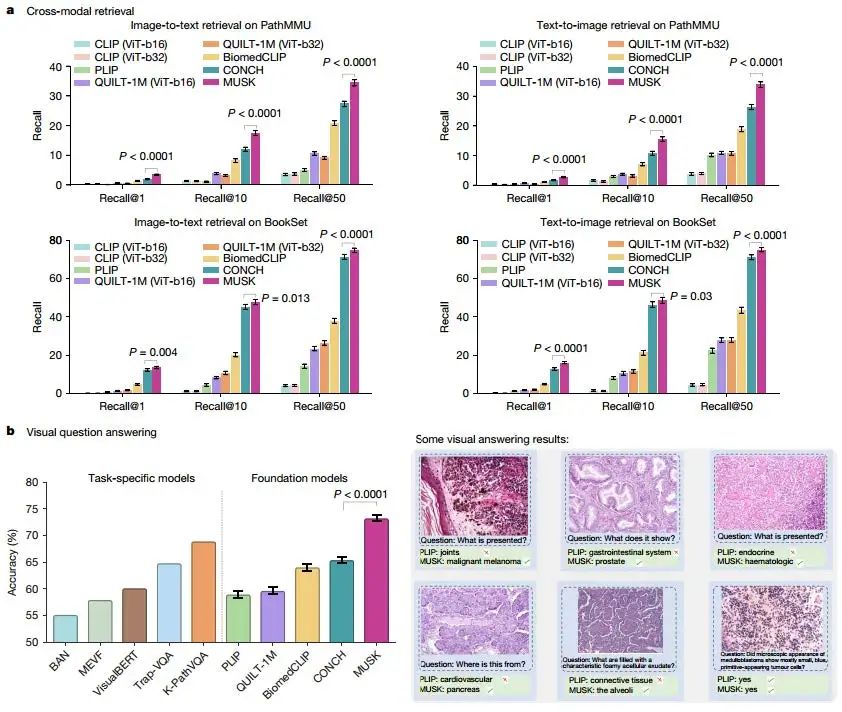 Fig2. 跨模式檢索和VQA
Fig2. 跨模式檢索和VQA3. 圖像檢索與分類
MUSK不僅在跨模態任務中表現優異,還可以作為獨立的圖像編碼器用于圖像檢索和分類任務。在零樣本和少樣本圖像分類中,MUSK在多個基準數據集上均超越了其他基礎模型。例如,在十樣本圖像分類中,MUSK在12個數據集中的10個上表現最佳。此外,MUSK在監督圖像分類中的平均準確率達到88.2%,顯著優于其他模型。這些結果證明了MUSK在病理圖像分類中的高效性和穩健性。
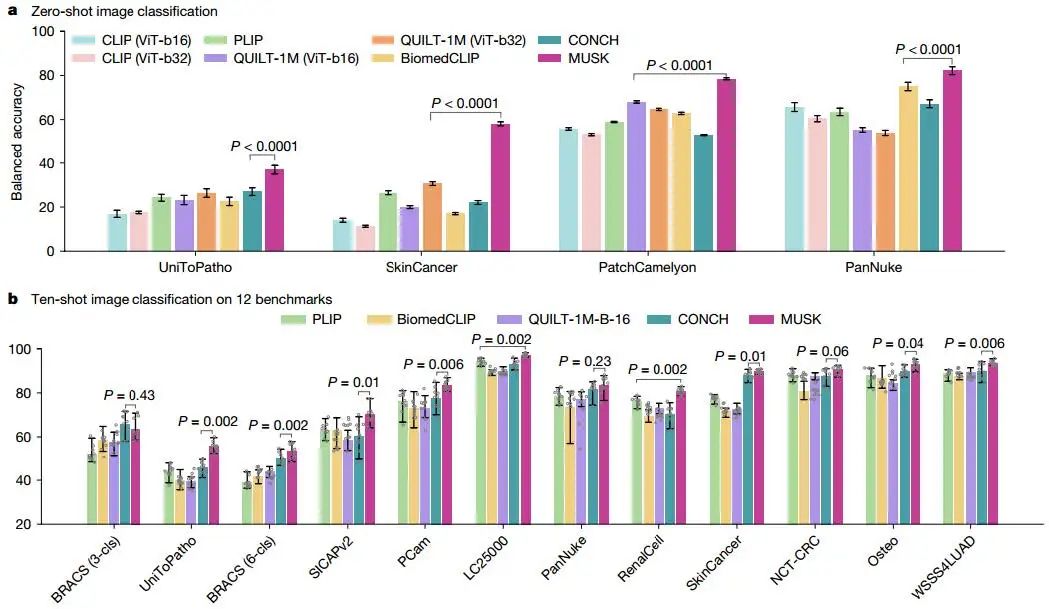 Fig3. 補丁級圖像分類
Fig3. 補丁級圖像分類4. 分子生物標志物預測
MUSK在從病理圖像中預測分子生物標志物方面展現了卓越性能。在乳腺癌受體狀態和腦腫瘤IDH突變狀態的預測任務中,MUSK的AUC值顯著高于其他病理學基礎模型。例如,在預測HER2狀態時,MUSK的AUC為0.826,優于GigaPath(0.786)和CONCH(0.771)。這表明MUSK能夠為精準腫瘤學提供有價值的分子標志物預測工具。
5. 黑色素瘤復發預測
MUSK在預測黑色素瘤復發方面表現出色。基于VisioMel數據集,MUSK在預測5年復發的AUC達到0.833,顯著優于其他視覺-語言基礎模型。通過結合臨床報告和病理圖像的多模態信息,MUSK進一步提高了預測準確性。此外,MUSK在90%敏感性閾值下的特異性顯著高于其他模型,可能幫助更多患者避免不必要的輔助治療。
6. 泛癌癥預后預測
MUSK在泛癌癥預后預測中展現了廣泛的應用潛力。基于TCGA數據集的16種癌癥類型,MUSK的平均c-index為0.747,顯著優于臨床風險因素和其他基礎模型。例如,在腎細胞癌中,MUSK的c-index達到0.887。通過Kaplan-Meier分析,MUSK能夠顯著分層低風險和高風險患者,為個性化治療提供了重要依據。
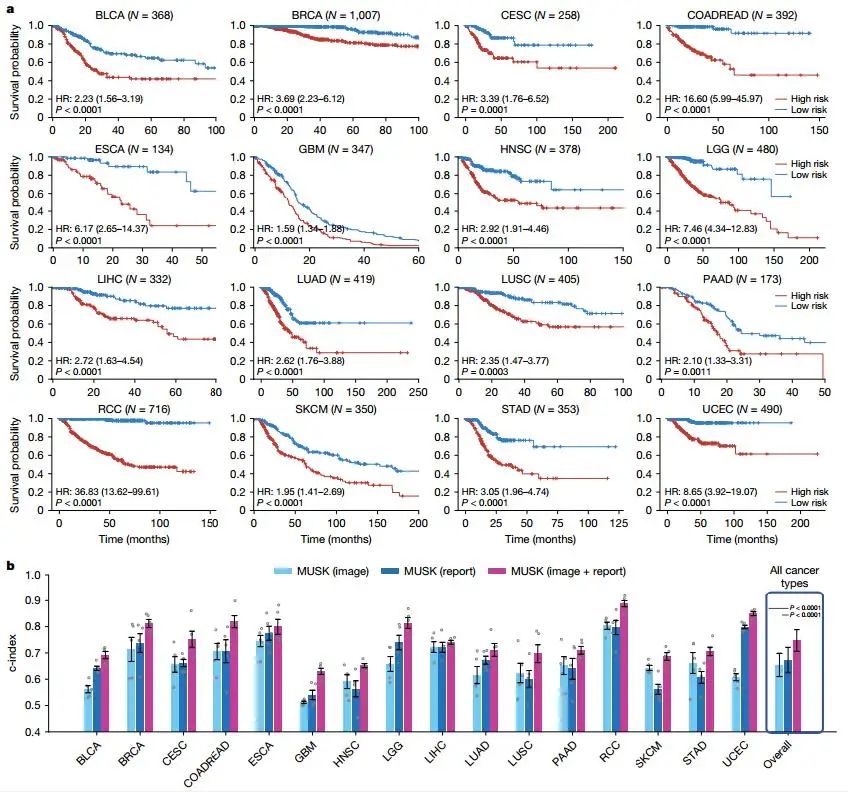 Fig4. 16種癌癥類型的預后預測
Fig4. 16種癌癥類型的預后預測7. 免疫治療反應預測
MUSK在預測免疫治療反應和結果方面表現優異。在晚期非小細胞肺癌和胃食管癌患者中,MUSK的AUC和c-index均顯著優于現有生物標志物和其他基礎模型。例如,在預測NSCLC患者PFS時,MUSK的c-index為0.705,優于腫瘤PD-L1表達的0.574。通過多模態數據整合,MUSK能夠識別可能從免疫治療中受益的患者,為臨床決策提供了有力支持。
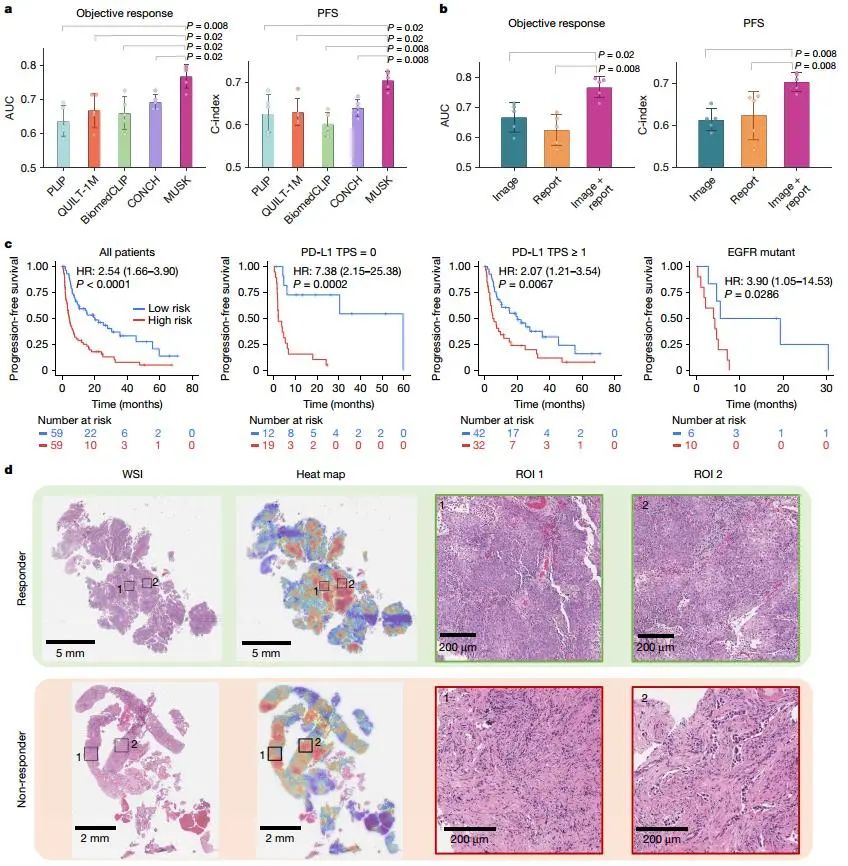 Fig5. 肺癌免疫治療反應預測
Fig5. 肺癌免疫治療反應預測四. 主要結論
本研究開發了一種名為“多模態統一掩碼建模變換器”(MUSK)的視覺-語言基礎模型,旨在利用大規模、未標注、未配對的圖像和文本數據。MUSK通過統一掩碼建模技術,預訓練了來自11,577名患者的5000萬張病理圖像和10億個病理相關文本標記。此外,它還進一步預訓練了100萬張病理圖像-文本對,以高效對齊視覺和語言特征。在無需或僅需少量額外訓練的情況下,MUSK在23個圖像塊級別和切片級別的基準測試中展現了卓越性能,涵蓋圖像到文本和文本到圖像的檢索、視覺問答、圖像分類以及分子生物標志物預測等任務。
此外,MUSK在結果預測方面也表現出色,包括黑色素瘤復發預測、泛癌預后預測以及肺癌和胃食管癌的免疫治療反應預測。MUSK成功整合了病理圖像和臨床報告中的互補信息,有望提高癌癥診斷的準確性和治療的精準性。
參考文獻
Xiang, Jinxi et al. “A vision-language foundation model for precision oncology.” Nature vol. 638,8051 (2025): 769-778.